Gemma vs Claude for SEO Scoring: What the 26-Point Gap Reveals

Most SEO advice sounds the same: write longer posts, use your keyword in the title, add a meta description, get backlinks. But what happens when you use AI to actually grade your existing content — and two different models disagree by 26 points on the same post?
That’s what happened when I ran my entire travel blog through two AI scoring systems: Google’s Gemma 4 (running locally on my machine via Ollama) and Claude Haiku (Anthropic’s fast model). Same posts, same prompt, wildly different results on some of them.
The disagreement was the useful part. A single AI score feels authoritative, but two scorers expose the assumptions hiding inside the rubric.
The Setup
I built a personal tool called Cerebro that manages SEO scoring across my content sites. It runs a mechanical pass first — checking the basics like title length, meta description, image alt text, tags — then layers on AI analysis. I added both Gemma and Claude as independent scorers so I could compare them side by side.
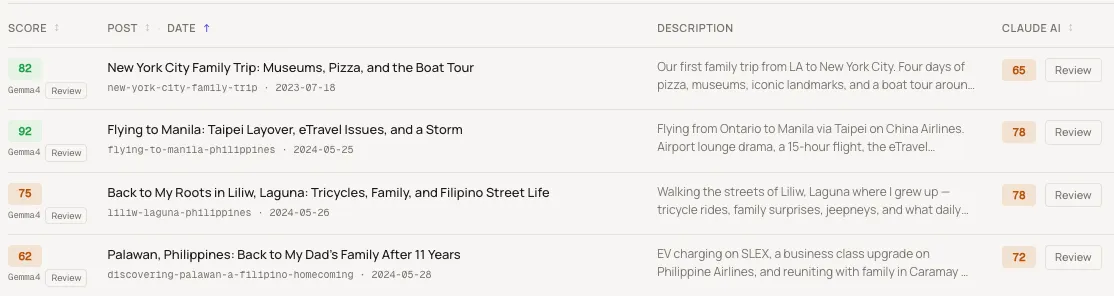
The table above shows the dual-score view I built: Gemma’s content score on the left of each row, Claude’s on the right. Where they agree, you have confidence. Where they diverge significantly, that’s a signal worth investigating.
Where They Agreed
For posts that follow a classic travel guide structure — hotel reviews, day trip itineraries, restaurant roundups — both models scored within 5–8 points of each other. A resort review that scored 88 on Gemma scored 80 on Claude. Close enough. Both were telling me the same thing: this post is solid.
Where They Didn’t
Here’s where it got interesting. A post about visiting the United Center in Chicago — a personal story about my first time back after 30 years, getting turned away from the Michael Jordan statue during the DNC — scored 52 on Gemma and 78 on Claude. A 26-point gap.
Gemma essentially said: this doesn’t look like a travel guide. No hotel, no restaurant list, no structured itinerary. Penalized.
Claude said: this is authentic first-hand experience. Someone who wants to know what it’s like to visit the United Center will find real value here.
Which one is right from an SEO perspective?
Why the Gap Matters
The gap matters because AI SEO scoring is not neutral. A model can reward the shape of a familiar search article even when the writing is thin. Another model can reward lived experience even when the structure is messier.
That means the score is not the answer. The score is a triage signal. When two models disagree, I treat that post as a review candidate instead of blindly accepting either recommendation.
The Review Panel
When I drill into any post, the tool shows me exactly what each model suggests changing — current vs. suggested title, description, tags, and hero image alt text side by side.
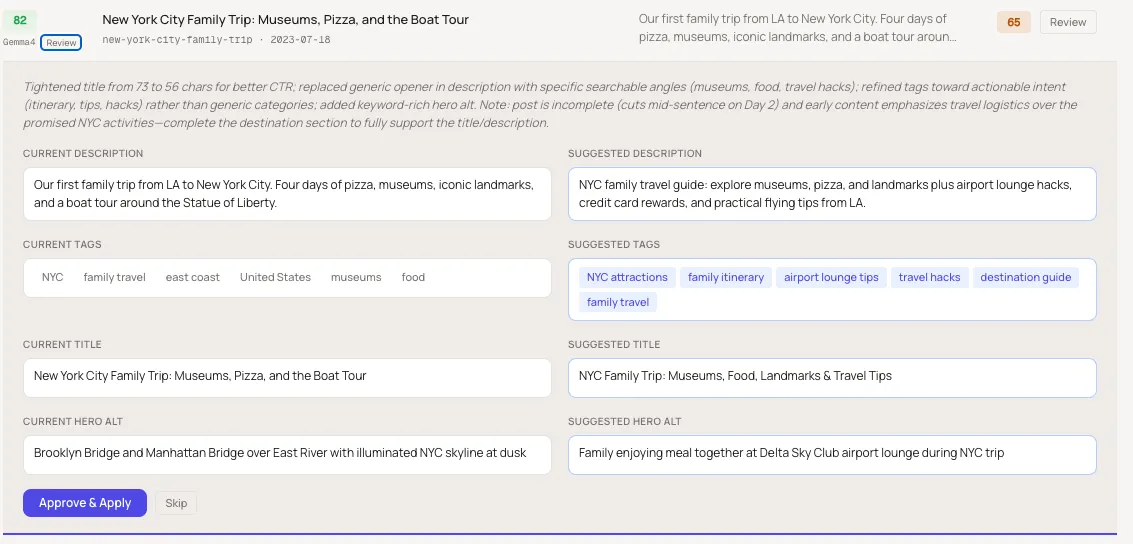
This is where it gets useful in practice. Claude’s suggestions tend to be more specific and search-intent aware — notice how the suggested description above reframes a general “family trip” into specific searchable angles: museums, food, travel hacks, airport lounge tips. That’s the difference between a description that describes your post and one that intercepts a search.
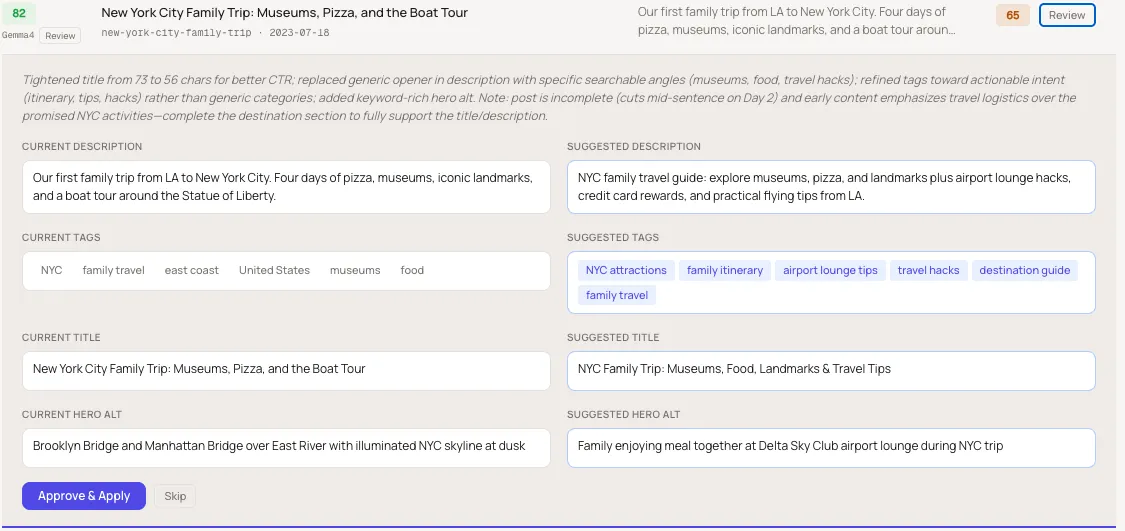
The tag suggestions follow the same logic: away from generic categories like “east coast” and “United States,” toward intent-specific terms like “airport lounge tips” and “family itinerary.”
The Honest Answer: Neither Fully, But One Is Closer
Neither model can see your backlink profile, keyword search volume, or how long people actually stay on your page — all things Google weighs heavily. But if you’re asking which scoring philosophy is more aligned with how Google evaluates content today, the answer is Claude.
Google’s helpful-content guidance and quality rater guidelines put real weight on E-E-A-T: Experience, Expertise, Authoritativeness, and Trustworthiness. The first E — Experience — is about first-hand, lived experience. A personal story about actually being somewhere, with real observations and honest opinions, is much closer to that direction than a generic guide assembled from search-result patterns.
Gemma is grading on the old rubric. The one that rewarded posts that looked like travel guides — structured, keyword-dense, predictably formatted. Google spent years training people to write that way, then decided that content wasn’t actually helpful and started demoting it.
So Which Score Should You Care About?
I use all three in combination:
- Mechanical scan first — fix the basics. Missing meta description? No image alt text? That’s free SEO you’re leaving on the table. Handle it immediately.
- Claude score for content quality — this tells you whether your post will actually satisfy the person who finds it. Prioritize low Claude scores for rewrites.
- Gemma as a structural check — if both Claude and Gemma score a post low, it genuinely needs work. If only Gemma is low, your post is probably fine and Gemma just doesn’t understand your brand voice.
Across my travel blog, Gemma averaged 83 and Claude averaged 78. Haiku is the tougher grader — five points lower on average — and I trust it more for that reason. A model that’s harder to impress is a more useful editor.
My Rule After This Test
If both models score a post low, rewrite it.
If Claude scores it low and Gemma scores it high, look for thin structure: the post may look optimized without saying enough.
If Gemma scores it low and Claude scores it high, do not flatten the voice just to satisfy a checklist. Instead, add light structure around the lived experience: clearer headings, a stronger intro, useful context, better metadata, and specific takeaways.
The bigger takeaway: SEO tools built on old assumptions will steer you wrong. The game changed. Write like a person who was actually there, then use the checklist to make that experience easier to find.
Leave a comment
Comments are moderated, so it may take a bit before yours appears. Your email is never published.